

Python을 활용한 시계열 이상 탐지


데이터에서 중요한 문제나 숨겨진 기회를 드러낼 수 있는 비정상적인 패턴을 어떻게 식별할 수 있을까요? 이상 탐지는 정상에서 벗어난 데이터를 식별하는 데 도움이 됩니다. 시계열 데이터는 시간의 추이에 따라 수집된 데이터로 구성되어 있으며, 추세와 계절성 패턴이 포함된 경우가 많습니다. 시계열 데이터의 이상은 이러한 패턴이 깨질 때 발생하기에 이상 탐지는 영업, 금융, 제조, 의료와 같은 산업에서 중요한 도구가 됩니다.
시계열 데이터는 계절성이나 추세와 같은 고유한 특성을 가지고 있기 때문에 이상치를 효과적으로 탐지하기 위해서는 전문적인 방법이 필요합니다. 이 블로그 글에서는 STL 분해와 LSTM 예측 등 시계열 데이터에서 이상치를 탐지하는 데 널리 사용되는 몇 가지 방법을 다루며, 처음 이해할 때 도움이 될 상세한 코드 예시도 함께 제공합니다.
비즈니스에서의 시계열 이상 탐지
시계열 데이터는 여러 비즈니스 및 서비스에서 매우 중요합니다. 많은 비즈니스에서 시간 경과에 따른 데이터를 타임스탬프와 함께 기록하여 시간 추이에 따른 변화를 분석하고 데이터를 비교할 수 있습니다. 시계열은 특정 기간 동안 특정 수량을 비교할 때 유용합니다(예: 데이터가 계절적 특성을 나타내는 연도별 비교).
매출 모니터링
계절성이 있는 시계열 데이터의 가장 일반적인 예는 매출 데이터입니다. 매출은 연중 공휴일과 계절의 영향을 많이 받기 때문에 계절성을 고려하지 않고 매출 데이터의 결론을 도출하기란 어려운 일입니다. 이런 이유로 매출 데이터에서 이상치를 분석하고 발견하는 일반적인 방법으로 STL 분해가 사용됩니다. 이는 이 글의 후반부에서 자세히 다뤄 보겠습니다.
금융
거래 및 주가와 같은 금융 데이터는 시계열 데이터의 대표적인 예입니다. 금융 업계에서는 이러한 데이터의 이상치를 분석하고 탐지하는 것이 일반적인 관행입니다. 예를 들어 자동 거래에 시계열 예측 모델을 사용할 수 있습니다. 이 글의 후반부에서 시계열 예측을 사용하여 주식 데이터의 이상치를 파악하는 방법을 살펴보겠습니다.
제조
시계열 이상 탐지의 또 다른 사용 사례는 생산 라인의 결함을 모니터링하는 것입니다. 기계가 모니터 역할을 하는 경우가 많아 여기에서 시계열 데이터가 제공되기도 합니다. 잠재적인 장애를 관리자에게 알리는 것이 중요하며, 이때 이상 탐지가 핵심적인 역할을 합니다.
제약 및 의료
제약 및 의료 업계에서는 사람의 생체 신호를 모니터링하고 이상치를 탐지할 수 있습니다. 이는 의료 연구에서 중요하지만 진단에서도 매우 중요한 문제입니다. 병원에 있는 환자의 바이탈 사인에 이상이 발생했을 때 즉시 치료가 이루어지지 않는다면, 그 결과는 치명적일 수 있습니다.
시계열 이상 탐지에 특수한 방법을 사용해야 하는 이유
시계열 데이터는 경우에 따라 기타 유형의 데이터처럼 취급할 수 없다는 점에서 특별하다고 할 수 있습니다. 예를 들어, 시계열 데이터에 트레이닝 테스트 분할을 적용할 때, 데이터의 순차적인 연속성 때문에 데이터를 섞을 수 없습니다. 이는 시계열 데이터를 딥러닝 모델에 적용할 때도 마찬가지입니다. 순차적 관계를 반영하기 위해 순환 신경망(RNN)이 흔히 사용되며, 트레이닝 데이터는 기간으로 입력되어 해당 기간 내에서 이벤트의 순서가 유지됩니다.
시계열 데이터는 무시할 수 없는 계절성과 추세를 가지고 있는 경우가 많기 때문에 더 특수합니다. 이러한 계절성은 24시간, 7일, 12개월 주기 등과 같이 몇몇 대표적인 형태로 나타날 수 있습니다. 아래 예시에서 볼 수 있듯이 계절성과 추세를 고려한 후에야 이상치를 판단할 수 있습니다.
시계열에서 이상 탐지에 사용되는 방법
시계열 데이터는 특수하기 때문에 이상치를 탐지하기 위한 특정 방법이 있습니다. 데이터 유형에 따라 이전 블로그 글에서 이상 탐지와 관련하여 언급한 몇 가지 방법과 알고리즘을 시계열 데이터에 사용할 수 있습니다. 그러나 그러한 방법은 시계열 데이터 전용으로 설계된 기법에 비해 이상 탐지의 신뢰성이 다소 떨어질 수 있습니다. 경우에 따라 여러 탐지 방법을 조합하여 탐지 결과를 재확인하면 위양성(FP) 또는 위음성(FN)을 방지할 수 있습니다.
STL 분해
계절성이 있는 시계열 데이터를 사용할 때 가장 인기 있는 방법 중 하나는 STL 분해로, LOESS(국지적 추정 산점도 평활화)를 사용한 계절적 추세 분해입니다. 이 방법은 계절성 추정치(알고리즘을 사용하여 제공되거나 결정된 기간), 추세(추정치), 잔차(데이터의 노이즈)를 사용하여 시계열을 분해합니다. STL 분해 도구를 제공하는 Python 라이브러리는 statsmodels 라이브러리입니다.
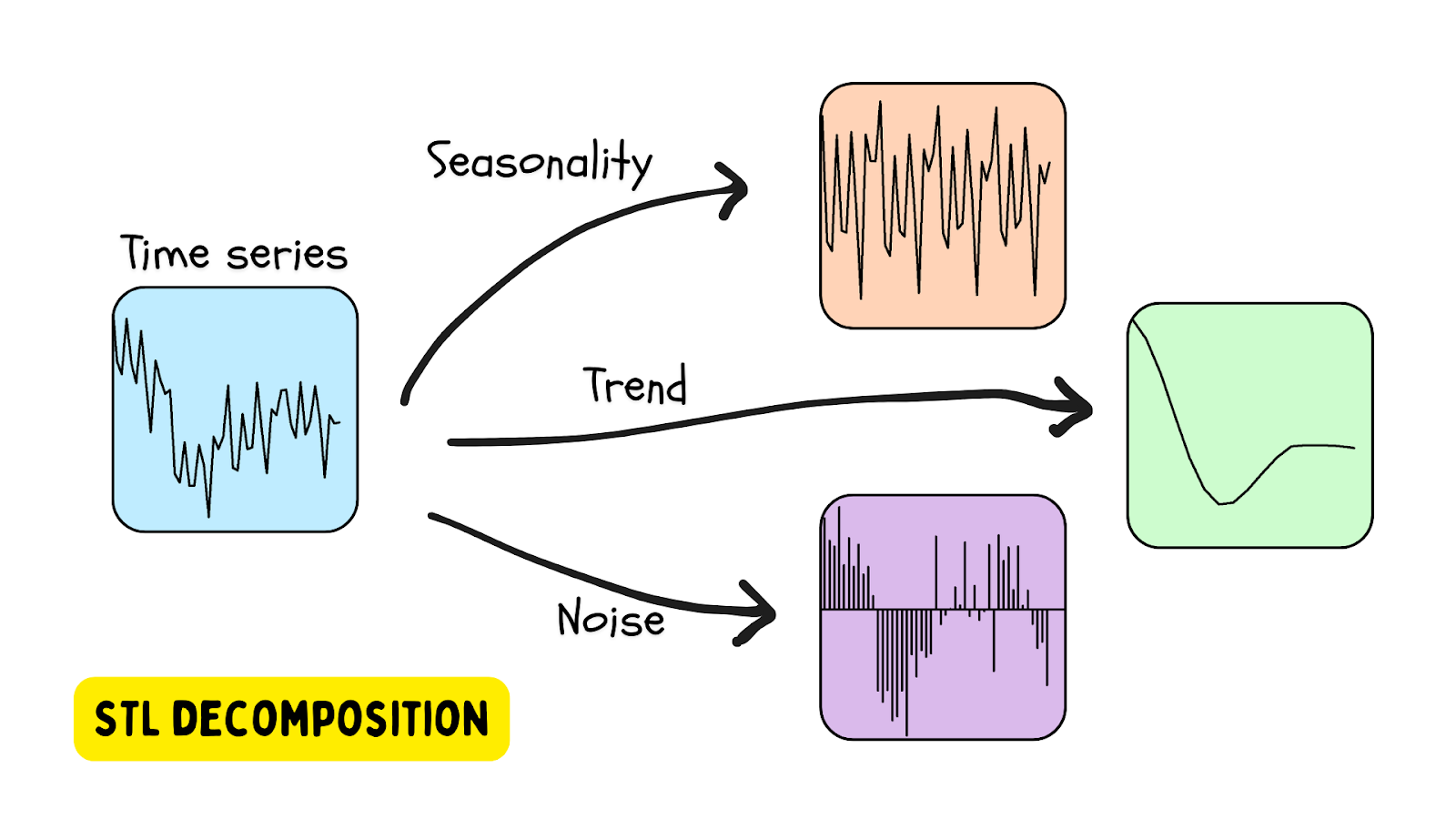
잔차가 특정 임곗값을 초과하면 이상이 탐지됩니다.
벌집 데이터에 STL 분해 사용
이전 블로그 글에서는 OneClassSVM과 IsolationForest 메서드를 사용하여 벌집에서 이상치를 탐지하는 방법을 살펴봤습니다.
이 튜토리얼에서는 statsmodels 라이브러리의 STL 클래스를 사용하여 벌집 데이터를 시계열로 분석해 보겠습니다. 시작하려면 다음 파일(requirements.txt)을 사용하여 환경을 설정합니다.
1. 라이브러리 설치
여기서는 Scikit-learn에서 제공하는 모델만 사용하므로 PyPI에서 statsmodels를 설치해야 합니다. 이 작업은 PyCharm에서 쉽게 수행할 수 있습니다.
Python Package(패키지) 창(IDE 왼쪽 하단에 있는 아이콘 선택)으로 이동하여 검색창에 statsmodels를 입력합니다.

우측에서 패키지에 대한 모든 정보를 확인할 수 있습니다. 설치하려면 Install package(패키지 설치)를 클릭하면 됩니다.
2. Jupyter Notebook 만들기
데이터 세트를 자세히 조사하기 위해 Jupyter Notebook을 만들어 PyCharm의 Jupyter Notebook 환경이 제공하는 도구를 활용해 보겠습니다.
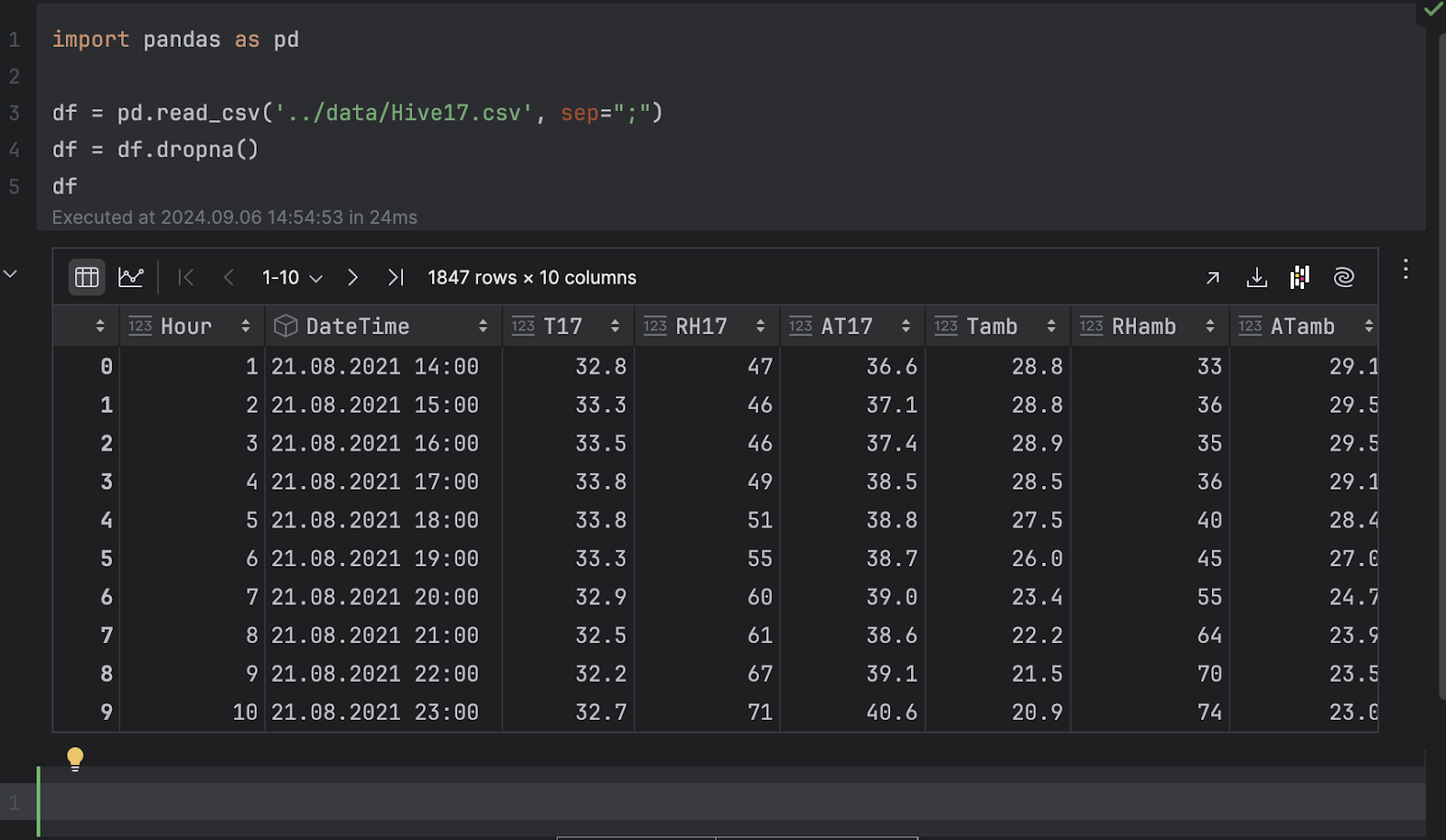
pandas를 가져와서 .csv 파일을 로드합니다.
import pandas as pd
df = pd.read_csv('../data/Hive17.csv', sep=";")
df = df.dropna()
df
3. 그래프로 데이터 검사
이제 데이터를 그래프로 살펴볼 수 있습니다. 여기서는 시간 경과에 따른 hive 17의 온도를 보고자 합니다. DataFrame 검사 도구에서 Chart view(차트 뷰)를 클릭한 다음 계열 설정에서 T17을 y축으로 선택합니다.

시계열로 표현된 온도 데이터는 많은 등락을 보입니다. 낮과 밤의 주기와 같이, 주기적인 움직임을 나타내므로 온도에 24시간 주기가 있다고 가정해도 무방합니다.
다음으로 시간에 따라 온도가 떨어지는 추세가 있습니다. DateTime 열을 살펴보면 8월부터 11월까지 날짜 범위가 있음을 알 수 있습니다. 데이터 세트의 Kaggle 페이지를 보면 데이터가 튀르키예에서 수집되었으므로, 여름에서 가을로의 전환이 시간이 지남에 따라 온도가 내려가는 현상을 설명해 준다는 것을 알 수 있습니다.
4. 시계열 분해
시계열 데이터를 이해하고 이상치를 탐지하기 위해 STL 분해를 수행해 보겠습니다. 이를 위해 statsmodels에서 STL 클래스를 불러와 온도 데이터에 적용하겠습니다.
from statsmodels.tsa.seasonal import STL stl = STL(df["T17"], period=24, robust=True) result = stl.fit()
분해가 작동하려면 기간을 입력해야 합니다. 앞서 언급했듯이, 24시간 주기가 있다고 가정해도 무방합니다.
문서에 따르면 STL은 시계열을 추세, 계절성, 잔차의 세 가지 구성 요소로 분해합니다. 분해된 결과를 더 명확하게 파악하기 위해 기본 제공된 plot 메서드를 사용할 수 있습니다.
result.plot()

Trend(추세) 및 Season(계절성) 플롯이 위의 가정과 잘 맞아떨어지는 것을 볼 수 있습니다. 하지만, 우리가 주목하는 것은 맨 아래에 있는 잔차 플롯으로, 이는 원래 시계열에서 추세와 계절 변동을 제거한 결과입니다. 잔차에서 극단적으로 크거나 작은 값은 이상치를 나타냅니다.
5. 이상치 임곗값
다음으로, 잔차 중 어떤 값을 이상치로 간주할지 결정해야 합니다. 이를 위해 잔차의 히스토그램을 살펴볼 수 있습니다.
result.resid.plot.hist()

이는 0을 중심으로 하는 정규 분포로 볼 수 있으며, 5 이상과 -5 이하의 롱 테일이 나타나는 형태이므로 임곗값을 5로 설정하겠습니다.
원래의 시계열에 이상치를 표시하기 위해 그래프에서 모든 이상치를 다음과 같이 빨간색으로 표시할 수 있습니다.
import matplotlib.pyplot as plt
threshold = 5
anomalies_filter = result.resid.apply(lambda x: True if abs(x) > threshold else False)
anomalies = df["T17"][anomalies_filter]
plt.figure(figsize=(14, 8))
plt.scatter(x=anomalies.index, y=anomalies, color="red", label="anomalies")
plt.plot(df.index, df['T17'], color='blue')
plt.title('Temperatures in Hive 17')
plt.xlabel('Hours')
plt.ylabel('Temperature')
plt.legend()
plt.show()

STL 분해 없이 주기와 추세가 포함된 시계열에서 이러한 이상치를 식별하기는 매우 어렵습니다.
LSTM 예측
시계열 데이터에서 이상치를 탐지하는 또 다른 방법은 딥러닝 기법을 사용해 해당 시계열 데이터를 예측하고, 각 데이터 포인트의 예상 결과를 추정하는 것입니다. 만약 예상값과 실제 데이터 포인트 사이의 차이가 매우 크다면, 이는 이상 데이터일 가능성이 있습니다.
순차 데이터 예측을 수행하는 대표적인 딥러닝 알고리즘 중 하나는 LSTM 모델이며, 이는 순환 신경망(RNN)의 한 종류입니다. LSTM 모델은 입력 게이트, 망각 게이트, 출력 게이트로 구성되어 있으며, 이러한 게이트는 모두 수치 행렬입니다. 이를 통해 중요한 정보가 다음 단계의 데이터로 전달될 수 있도록 합니다.

시계열 데이터는 순차적 데이터로, 데이터 포인트의 순서가 순차적으로 정해져 있으며 임의로 섞여서는 안 됩니다. 이러한 특성 때문에, 특정 시점의 결과를 예측하는 데에는 LSTM 모델이 효과적인 딥러닝 모델입니다. 이렇게 예측한 값은 실제 데이터와 비교할 수 있으며, 특정 임곗값을 설정해 실제 데이터가 이상치인지 여부를 판단할 수 있습니다.
주가 데이터에서 LSTM 예측 활용
이제 지난 5년간 Apple 주가 데이터에서 이상치를 탐지하기 위한 새로운 Jupyter 프로젝트를 시작해 보겠습니다. 이 주가 데이터 세트는 최신 데이터를 보여줍니다. 이 블로그 글의 내용을 따라 하고 싶다면 여기에서 사용되는 데이터 세트를 다운로드하면 됩니다.
1. Jupyter 프로젝트 시작
새 프로젝트를 시작할 때 데이터 과학에 최적화된 Jupyter 프로젝트를 만들도록 선택할 수 있습니다. New Project(새 프로젝트) 창에서 Git 저장소를 만들고 환경 관리에 사용할 conda 설치를 결정할 수 있습니다.

프로젝트를 시작하면 예시 Notebook이 표시됩니다. 이 연습을 위해 새 Jupyter Notebook을 시작합니다.

그런 다음 requirements.txt를 설정해 보겠습니다. pandas, matplotlib, 그리고 PyPI에서 torch라는 이름으로 제공되는 PyTorch가 필요합니다. PyTorch는 conda 환경에 포함되어 있지 않으므로 PyCharm에서 패키지가 누락되었다고 알려줍니다. 패키지를 설치하려면 전구를 클릭하고 Install all missing packages(누락된 모든 패키지 설치)를 선택합니다.

2. 데이터 로드 및 검사
다음으로, 데이터 폴더에 apple_stock_5y.csv 데이터 세트를 넣고 pandas DataFrame으로 로드하여 검사해 보겠습니다.
import pandas as pd
df = pd.read_csv('data/apple_stock_5y.csv')
df
대화형 테이블을 사용하면 누락된 데이터가 있는지 쉽게 확인할 수 있습니다.

누락된 데이터는 없지만 한 가지 문제가 있습니다. 종가/현재가를 사용하고 싶지만 숫자 데이터 유형이 아닙니다. 변환을 수행하고 데이터를 다시 검사해 보겠습니다.
df["Close/Last"] = df["Close/Last"].apply(lambda x: float(x[1:])) df
이제 대화형 테이블을 통해 해당 가격을 확인할 수 있습니다. 왼쪽의 플롯 아이콘을 클릭하면 플롯이 생성됩니다. 기본적으로 Date(날짜)를 x축으로, Volume(거래량)을 y축으로 사용합니다. Close/Last(종가/현재가)를 검사할 것이므로, 오른쪽의 톱니바퀴 아이콘을 클릭하여 설정으로 이동한 다음 Close/Last를 y축으로 선택합니다.

3. LSTM을 위한 트레이닝 데이터 준비
다음으로 LSTM 모델에 사용할 트레이닝 데이터를 준비해야 합니다. 다음 가격을 예측하기 위해, 각각 기간을 나타내는 벡터 시퀀스(x축)를 준비해야 합니다. 다음 가격은 또 다른 시퀀스(목표값 y)를 형성합니다. 여기서 lookback 변수를 사용해 이 기간의 길이를 선택할 수 있습니다. 아래 코드는 시퀀스 x와 y를 생성하고, 이후 PyTorch tensor로 변환됩니다.
import torch
lookback = 5
timeseries = df[["Close/Last"]].values.astype('float32')
X, y = [], []
for i in range(len(timeseries)-lookback):
feature = timeseries[i:i+lookback]
target = timeseries[i+1:i+lookback+1]
X.append(feature)
y.append(target)
X = torch.tensor(X)
y = torch.tensor(y)
print(X.shape, y.shape)
일반적으로 기간이 길수록 입력 벡터가 크기 때문에 모델도 커집니다. 그러나 기간이 길수록 입력 시퀀스가 짧아지므로 이 검토 기간은 균형을 맞춰 결정해야 합니다. 여기서는 5로 시작하지만 다른 값으로 자유롭게 시도하여 차이점을 확인해 보세요.
4. 모델 빌드 및 트레이닝
모델을 트레이닝하기 전에 PyTorch에서 nn 모듈을 사용하여 클래스를 생성하고 모델을 빌드할 수 있습니다. nn 모듈은 다양한 신경망 레이어와 같은 구성 요소를 제공합니다. 이 연습에서는 간단한 LSTM 레이어와 선형 레이어를 빌드해 보겠습니다.
import torch.nn as nn
class StockModel(nn.Module):
def __init__(self):
super().__init__()
self.lstm = nn.LSTM(input_size=1, hidden_size=50, num_layers=1, batch_first=True)
self.linear = nn.Linear(50, 1)
def forward(self, x):
x, _ = self.lstm(x)
x = self.linear(x)
return x
다음으로 모델을 트레이닝하겠습니다. 모델을 트레이닝하기 전에 옵티마이저, 예측된 y 값과 실제 y 값 사이의 손실을 계산하는 데 사용되는 손실 함수, 그리고 학습 데이터를 입력할 데이터 로더를 만들어야 합니다.
import numpy as np import torch.optim as optim import torch.utils.data as data model = StockModel() optimizer = optim.Adam(model.parameters()) loss_fn = nn.MSELoss() loader = data.DataLoader(data.TensorDataset(X, y), shuffle=True, batch_size=8)
이미 기간이 생성되어 있기 때문에 데이터 로더가 입력을 섞을 수 있습니다. 이에 따라 각 기간에서 순차적 관계가 유지됩니다.
트레이닝은 각 에포크를 순회하는 for 루프를 사용하여 수행됩니다. 100 에포크마다 손실을 출력하고 모델이 수렴하는 과정을 관찰할 것입니다.
n_epochs = 1000
for epoch in range(n_epochs):
model.train()
for X_batch, y_batch in loader:
y_pred = model(X_batch)
loss = loss_fn(y_pred, y_batch)
optimizer.zero_grad()
loss.backward()
optimizer.step()
if epoch % 100 != 0:
continue
model.eval()
with torch.no_grad():
y_pred = model(X)
rmse = np.sqrt(loss_fn(y_pred, y))
print(f"Epoch {epoch}: RMSE {rmse:.4f}")
1000 에포크로 시작했지만 모델은 비교적 빠르게 수렴합니다. 최적의 결과를 얻기 위해 트레이닝용 에포크 수는 자유롭게 조정해 보셔도 좋습니다.
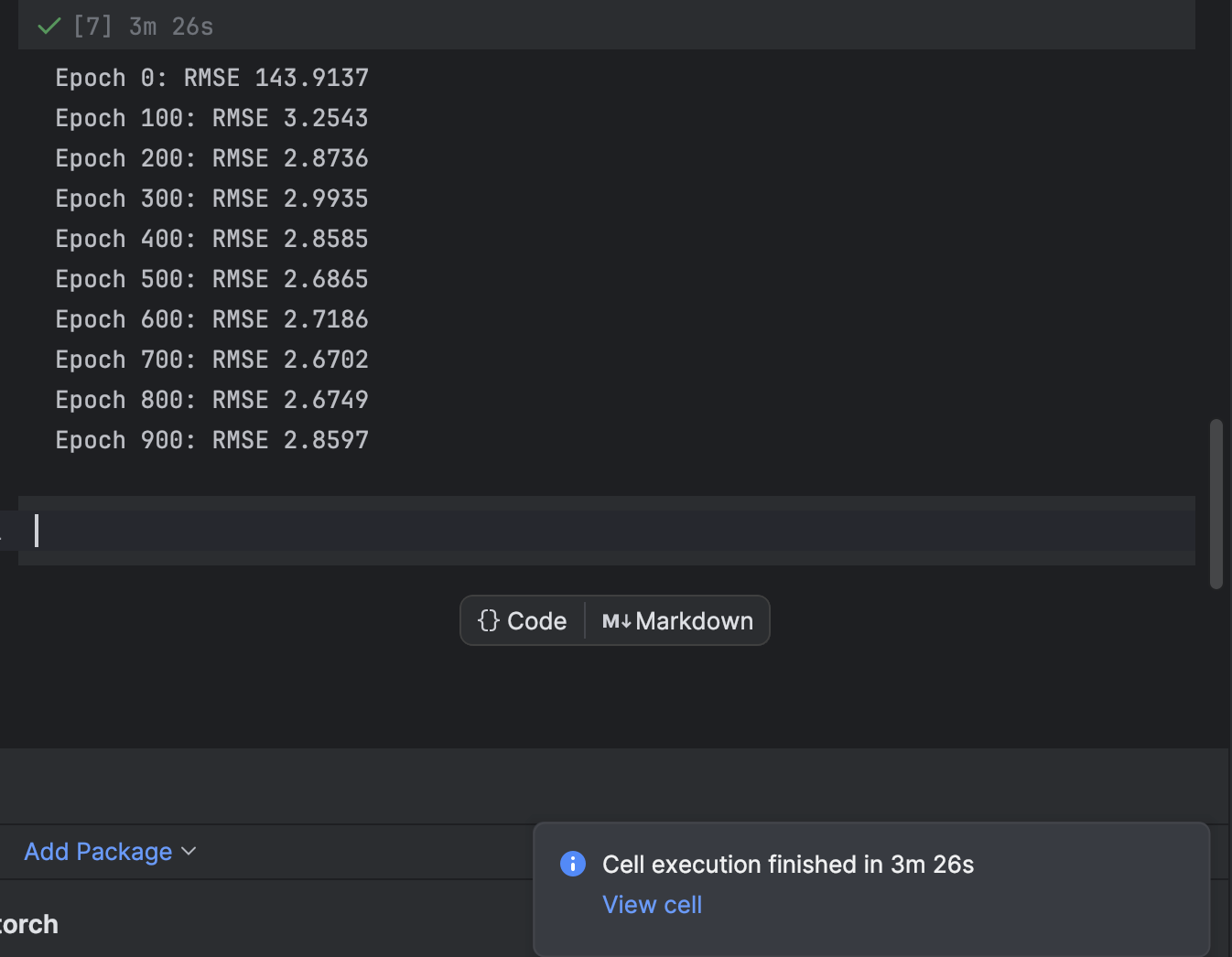
PyCharm에서는 실행에 시간이 걸리는 셀의 경우, 남은 시간을 알려주는 알림과 해당 셀로 바로 이동할 수 있는 바로가기를 제공합니다. 이 기능은 Jupyter Notebook에서 머신러닝 모델, 특히 딥러닝 모델을 트레이닝할 때 매우 유용합니다.
5. 예측 플롯 및 오류 찾기
다음으로 예측을 생성하고 실제 시계열과 함께 이를 플롯으로 생성합니다. 이때 실제 시계열 데이터와 형식을 맞추기 위해 2D np 계열을 생성해야 합니다. 실제 시계열 데이터는 파란색, 예측 시계열 데이터는 빨간색으로 표시됩니다.
import matplotlib.pyplot as plt
with torch.no_grad():
pred_series = np.ones_like(timeseries) * np.nan
pred_series[lookback:] = model(X)[:, -1, :]
plt.plot(timeseries, c='b')
plt.plot(pred_series, c='r')
plt.show()

주의 깊게 관찰하면 예측 값과 실제 값이 완벽하게 일치하지 않는다는 것을 알 수 있습니다. 그러나 대부분의 예측은 비교적 잘 맞는 편입니다.
오차를 면밀히 검사하기 위해 오차 시계열을 만들고 대화형 테이블을 사용하여 관찰할 수 있습니다. 여기서는 절대 오차를 사용합니다.
error = abs(timeseries-pred_series) error
설정을 사용하여 절대 오차 값을 x축으로 하고 해당 값의 개수를 y축으로 하는 히스토그램을 만듭니다.

6. 이상 임곗값을 결정하고 시각화
대부분의 포인트는 6 미만의 절대 오차를 가지므로 이를 이상치 임곗값으로 설정할 수 있습니다. 벌집 데이터의 이상치 작업과 유사한 방식으로 그래프에 이상 데이터 포인트를 플롯으로 생성할 수 있습니다.
threshold = 6
error_series = pd.Series(error.flatten())
price_series = pd.Series(timeseries.flatten())
anomalies_filter = error_series.apply(lambda x: True if x > threshold else False)
anomalies = price_series[anomalies_filter]
plt.figure(figsize=(14, 8))
plt.scatter(x=anomalies.index, y=anomalies, color="red", label="anomalies")
plt.plot(df.index, timeseries, color='blue')
plt.title('Closing price')
plt.xlabel('Days')
plt.ylabel('Price')
plt.legend()
plt.show()

요약
시계열 데이터는 비즈니스 및 과학 연구를 포함한 많은 분야에서 사용되는 일반적인 형태의 데이터입니다. 시계열 데이터의 순차적 특성으로 인해 이상 파악을 위한 특별한 방법과 알고리즘이 사용됩니다. 이 블로그 글에서는 계절성과 추세를 제거하기 위해 STL 분해를 사용하여 이상치를 식별하는 방법을 보여 드렸습니다. 또한 딥러닝과 LSTM 모델을 활용해 예측된 추정치와 실제 데이터를 비교하여 이상치를 파악하는 방법도 설명했습니다.
PyCharm을 사용하여 이상 탐지
PyCharm Professional의 Jupyter 프로젝트를 사용하면 수많은 데이터 파일과 Notebook으로 이상 탐지 프로젝트를 쉽게 구성할 수 있습니다. 이상치를 확인하기 위한 그래프 출력을 생성할 수 있으며, PyCharm에서는 이러한 플롯을 매우 쉽게 확인할 수 있습니다. 자동 완성 제안과 같은 다른 기능을 사용하면 모든 Scikit-learn 모델과 Matplotlib 플롯 설정을 아주 쉽게 탐색할 수 있습니다.
PyCharm을 사용하여 데이터 과학 프로젝트를 강화하고 데이터 과학 워크플로를 간소화하기 위해 제공되는 데이터 과학 기능도 확인해 보세요.

Subscribe to PyCharm Blog updates




